A week into running the Shoothill AI Signal live, three patterns are already clear. None of them are what most people assume about AI.
When we started building signal.shoothill.ai, the working theory was straightforward. Pick the major AI models, ask them the same fixed questions every hour, watch what happens. We expected the data to confirm what we’d been telling clients for the past year: that these models drift, that the drift is invisible from the outside, and that businesses running AI workflows have been doing so without a safety net.
The data has confirmed that. It’s also shown us three things we weren’t expecting, or weren’t expecting to see this quickly. They’re worth setting out, because if your business is running AI anywhere, they probably affect you more than you think.
1. The cheap models behave very differently from the flagship ones
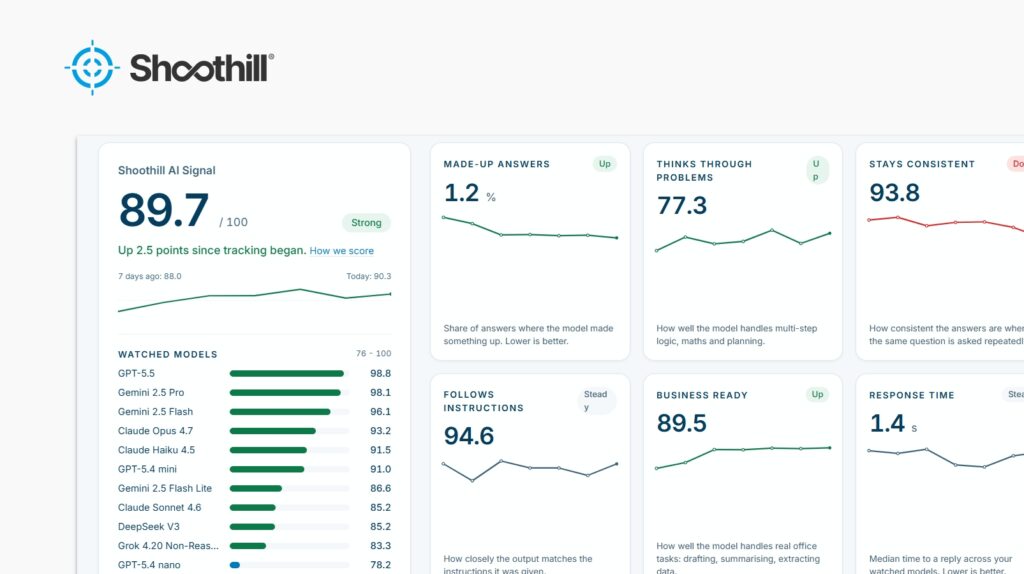
Most coverage of AI focuses on the top of the stack: GPT-5.5, Gemini 2.5 Pro, Claude Opus 4.7. These are the models that get benchmarked, written about, and used in keynotes. They’re also the most expensive to run, which is why almost no business actually uses them at scale for production workflows.
What businesses actually run is the cheap stuff. GPT-5.4 mini. Gemini 2.5 Flash Lite. Claude Haiku 4.5. The variants priced low enough that you can call them millions of times a month without the bill hurting. These are the models behind the AI features in your CRM, your helpdesk, your document processing, your internal chatbot.
And the gap between the flagship and the cheap variant is enormous. On our index, the top model scores 98.1. The bottom one scores 77.7. That’s a twenty-point difference on a scale where one point is meaningful. The hallucination rates tell the same story: the best model invents facts on 2% of answers; some of the cheaper models do it on 5% or more.
This matters because if you signed up for “ChatGPT for our team” and your IT supplier quietly routed it through the cheaper model to keep costs down, the AI you’re using is not the AI in the demos. It’s the AI scoring 78, not the AI scoring 98. That’s a different product. You should know which one you’re paying for.
2. Models slip more often than they improve, in the short term
We assumed we’d see a roughly even split between models getting better and models getting worse week-to-week. That’s not what’s happening so far. The shifts we’ve caught in the first weeks of running the index have skewed downward. Models slipping a few points. Specific pillars (instruction-following, consistency) degrading while overall scores stay flat. The kind of drift that wouldn’t be visible from inside any one application.
The reason for this is probably mundane. Providers are constantly making changes, and a lot of those changes optimise for things that don’t show up in our tests: speed, cost, safety filtering, multilingual performance. When a provider tunes a model to refuse a wider category of request, accuracy on legitimate business tasks can drop as a side effect. When they optimise for inference cost, instruction-following sometimes loosens. The headline capability stays roughly the same. The reliability for specific business workflows wobbles.
This is the strongest argument we’ve seen yet for the basic AI Signal proposition. If a tool you depend on is getting worse on the dimensions that matter to your business, even by a small amount, you want to know about it the same week. Not the next quarter, when somebody finally audits the outputs.
3. “Stays consistent” is the most under-discussed metric in AI
When people talk about AI quality, they almost always talk about accuracy. Does it get the right answer? That’s the headline. But for a business running an AI tool in a real workflow, consistency matters at least as much, and often more.
Here’s why. If you’re using AI to draft customer responses, summarise meetings, or extract data from invoices, the question isn’t just “is this answer correct” but “is this answer the same answer it would have given last week, and the week before, and the week before that?” Inconsistent outputs break process. They create work for the humans checking the AI. They make audit trails meaningless. They erode the trust that justifies using AI in the first place.
Our top models score in the high 90s on consistency. The cheaper ones drop. And consistency is one of the dimensions most likely to shift when a provider changes a model under the hood, because it’s a side effect of randomness in how the model generates text. Tweaking that randomness for any reason can leave accuracy untouched while quietly making the same prompt return slightly different answers each time.
If you remember one thing from the AI Signal data so far, make it this: ask your AI suppliers what their consistency score looks like. Most won’t have one. That’s the answer.
What this means in practice
If you’ve got AI running in your business, three things are worth doing this week.
First, find out which specific model your tools are calling. Not “GPT” or “Claude” but the exact version. The performance gap between models with similar names is enormous, and you may be paying for something other than what you think you’re paying for.
Second, watch the consistency dimension as closely as accuracy. A drop in consistency is often the first sign that a provider has changed something. By the time it shows up in accuracy too, the damage is already in your outputs.
Third, make sure somebody outside the supplier is watching. The AI Signal is one option. There are others. The principle is the same either way: the company selling you the AI tool should not be the only source of truth on whether it’s still working.
The models will keep changing. The data will keep getting more interesting. We’ll keep publishing what we find.